近年,人為的ミスに起因する交通事故の抑制につながる自動運転システムが注目されています.自動運転の鍵となるのは,ドライバーの意思決定を自動化することであり,そのためには人間の運転行動を適切にモデル化することが不可欠です.特に,複雑な運転行動を人手でルール化することは困難であるため,データから行動原理を学習する逆強化学習への期待が高まっています.
これまでの取り組みでは,安全な行動データ(正例)と危険な行動データ(負例)を用いて,事故を回避するための意思決定を模倣する手法が提案されてきました.しかしながら,実際の運転行動においては,危険な挙動は軌跡全体にわたって現れるわけではなく,ごく一部の時間に局所的に現れることが多くあります.この性質を無視して軌跡全体を負例として扱うと,本来は安全な行動まで負例に含まれてしまい,正例との間にコンフリクトが生じ,学習が不安定になるという問題がありました.
そこで我々は,危険行動の時間的局所性に着目し,負例を時間的に限定して導入する逆強化学習手法を提案しました(趙ら,ロボティクス・メカトロニクス講演会2023/Robomech 2023,および IEEE Intelligent Vehicles Symposium 2024).危険な挙動が現れる区間のみを負例として扱い,それ以外の区間は正例として扱うことで,正例と負例の矛盾を緩和し,学習の収束性と安定性を改善できることを示しました(図1).
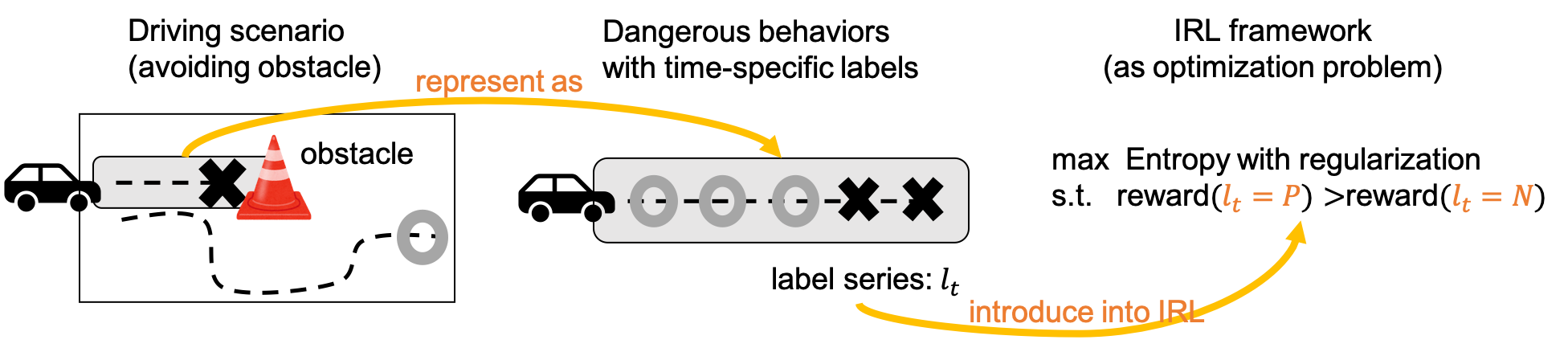
図. 1: 時間的局所性に着目した負例情報の活用
一方で,我々が最終的に目指しているのは,連続状態空間においても破綻せず,かつ安全性を一貫して担保できる運転行動モデル,すなわちcontinuousかつsafeな逆強化学習の実現です.しかし,このようなモデルを実現するためには,離散的な設定での安定化だけでは不十分であり,連続状態空間における学習の不安定性にも対処する必要があります.
最大エントロピー逆強化学習では,報酬関数の推定において分配関数の近似が必要となり,そのために軌跡サンプリングが用いられます.しかし,従来のモーションプランナは状態空間全体を広く探索する一方で,人間のデモンストレーションに近い領域を効率的に探索できない場合があり,得られるサンプルがエキスパートの行動を十分に反映しないという問題がありました.その結果,報酬推定の精度が低下し,連続状態空間における学習の安定性が損なわれる可能性があります.
この課題に対し,我々は人間のデモンストレーション情報を活用したガイド付きモーションプランニングを導入しました(趙ら,IEEE Access,2025).デモンストレーションから得られる確率分布に基づいて軌跡サンプリングを誘導することで,状態空間全体の探索性を保ちながら,エキスパート側の軌跡の近傍を重点的にサンプリングすることが可能となります.これにより,サンプル軌跡とエキスパートの軌跡の重なりを高め,連続状態空間においても安定した報酬学習を実現しました.
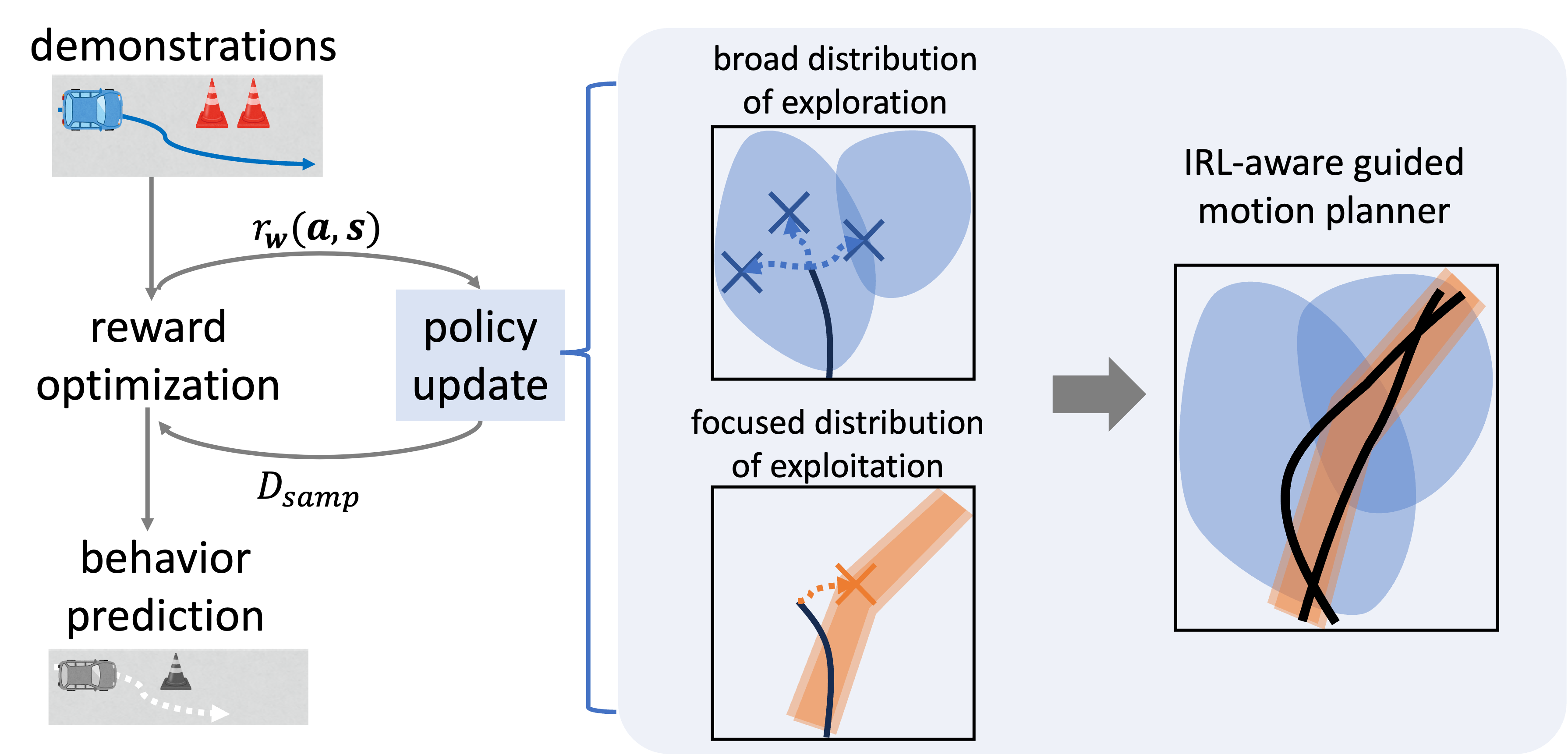
図2:連状態空間IRLの学習の効率化・安定化のためのデモンストレーション情報を活用したモーションプラナー
さらに,我々が目指すcontinuousかつsafeな運転行動モデルの実現においては,実環境データの持つ性質そのものにも向き合う必要があります.安全上の制約から,衝突や重大な交通違反といった失敗事象は発生頻度が低く,結果として取得できるデータは疎になります.このような状況では,状態訪問頻度に基づく従来の逆強化学習手法では報酬推定のばらつきが大きくなり,連続性と安全性の両立が困難となります.
そこで我々は,これらの課題に対して単純に既存手法を組み合わせるのではなく,状態ごとの安全性を直接扱うための行動識別器を導入した新たな逆強化学習フレームワークを提案しました(趙ら,IEEE International Conference on Intelligent Transportation Systems 2025).この手法では,識別器が環境コンテキストに基づいて各状態に安全ラベルを付与し,報酬推定と並行して学習されます.これにより,追加の制約付き最適化を導入することなく,状態単位での細粒度な安全性情報を統合的に取り込むことが可能となり,疎な失敗データ下においても,連続状態空間における安定性と安全性の両立を実現します(図3).
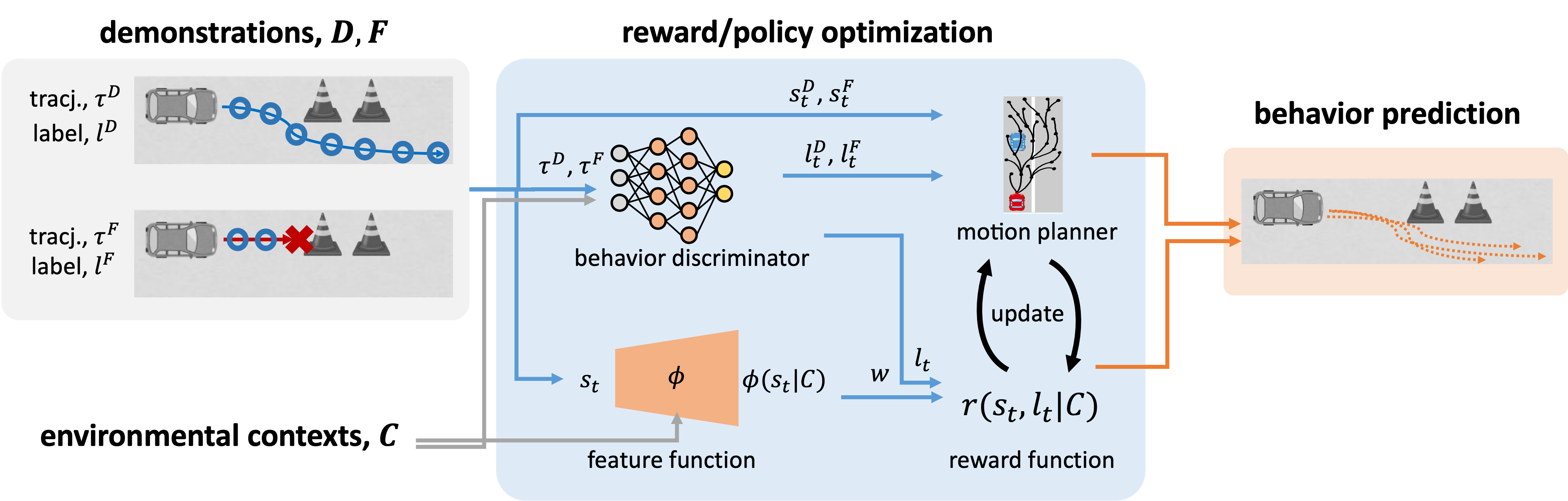
図3:疎な負例データに対する判別モデルを導入した時間的局所性負例導入IRLのフレームワーク
以上のように,本研究では,危険行動の時間的局所性,連続状態空間におけるサンプリングの課題,および失敗事象の希少性に起因するデータの疎性といった,現実の運転データが持つ不完全性に段階的に取り組んできました.これらを踏まえ,最終的にはcontinuousかつsafeな運転行動のモデル化を実現する逆強化学習フレームワークへと発展させました.