Learning driving policies that ensure safety is a fundamental problem in autonomous driving. A common approach is to learn decision-making policies for accident avoidance by leveraging both safe behavioral data (positive examples) and unsafe behavioral data (negative examples). However, in real-world driving behavior, unsafe actions do not typically persist throughout an entire trajectory; rather, they tend to occur only within limited temporal segments. Ignoring this property and treating entire trajectories as negative examples inevitably includes segments that are in fact safe, leading to conflicts with positive examples and resulting in unstable learning. To address this issue, we focus on the temporal locality of unsafe behavior and propose an inverse reinforcement learning method that incorporates negative examples in a temporally constrained manner (IEEE IV 2024). By treating only the segments in which unsafe behavior occurs as negative examples and the remaining segments as positive examples, we alleviate the conflict between positive and negative data and demonstrate improved convergence and stability of learning (Fig. 1).
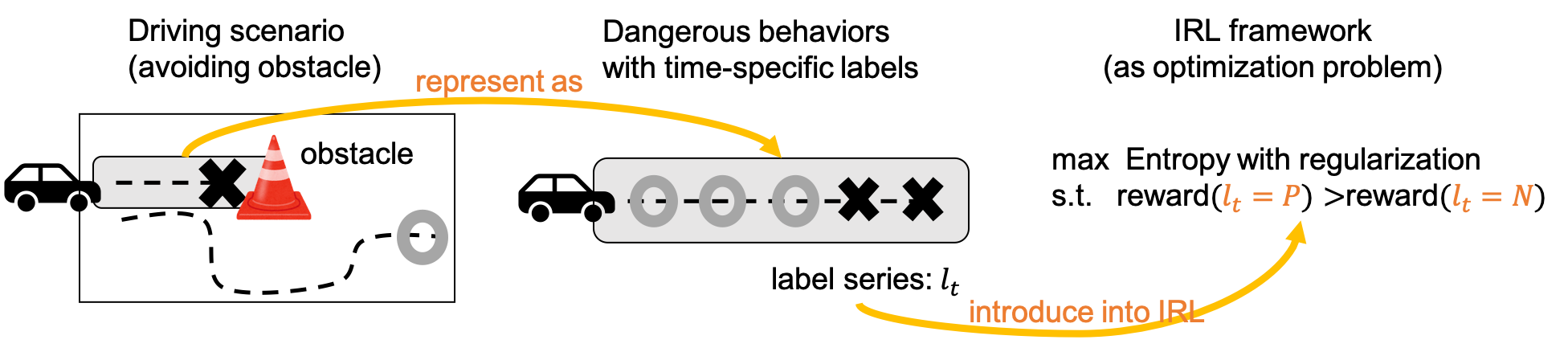
Figure 1: Utilization of negative information with a focus on temporal locality
On the other hand, our ultimate objective is to realize a driving behavior model that does not break down in continuous state spaces while consistently ensuring safety, namely, continuous and safe inverse reinforcement learning. However, achieving such a model requires not only stabilization in discrete settings but also addressing the instability inherent in learning within continuous state spaces.
In maximum entropy inverse reinforcement learning, estimation of the reward function requires approximation of the partition function, for which trajectory sampling is employed. Conventional motion planners, however, tend to explore the state space broadly, and may fail to efficiently explore regions close to human demonstrations. As a result, the sampled trajectories do not sufficiently reflect expert behavior, leading to degraded reward estimation accuracy and potential instability in learning within continuous state spaces.
To address this issue, we introduce a guided motion planning approach that leverages human demonstration information (Zhao et al., IEEE Access, 2025). By guiding trajectory sampling based on the probability distribution derived from demonstrations, our method enables focused sampling in the vicinity of expert trajectories while maintaining exploration over the entire state space. This increases the overlap between sampled trajectories and expert trajectories, thereby achieving stable reward learning even in continuous state spaces.
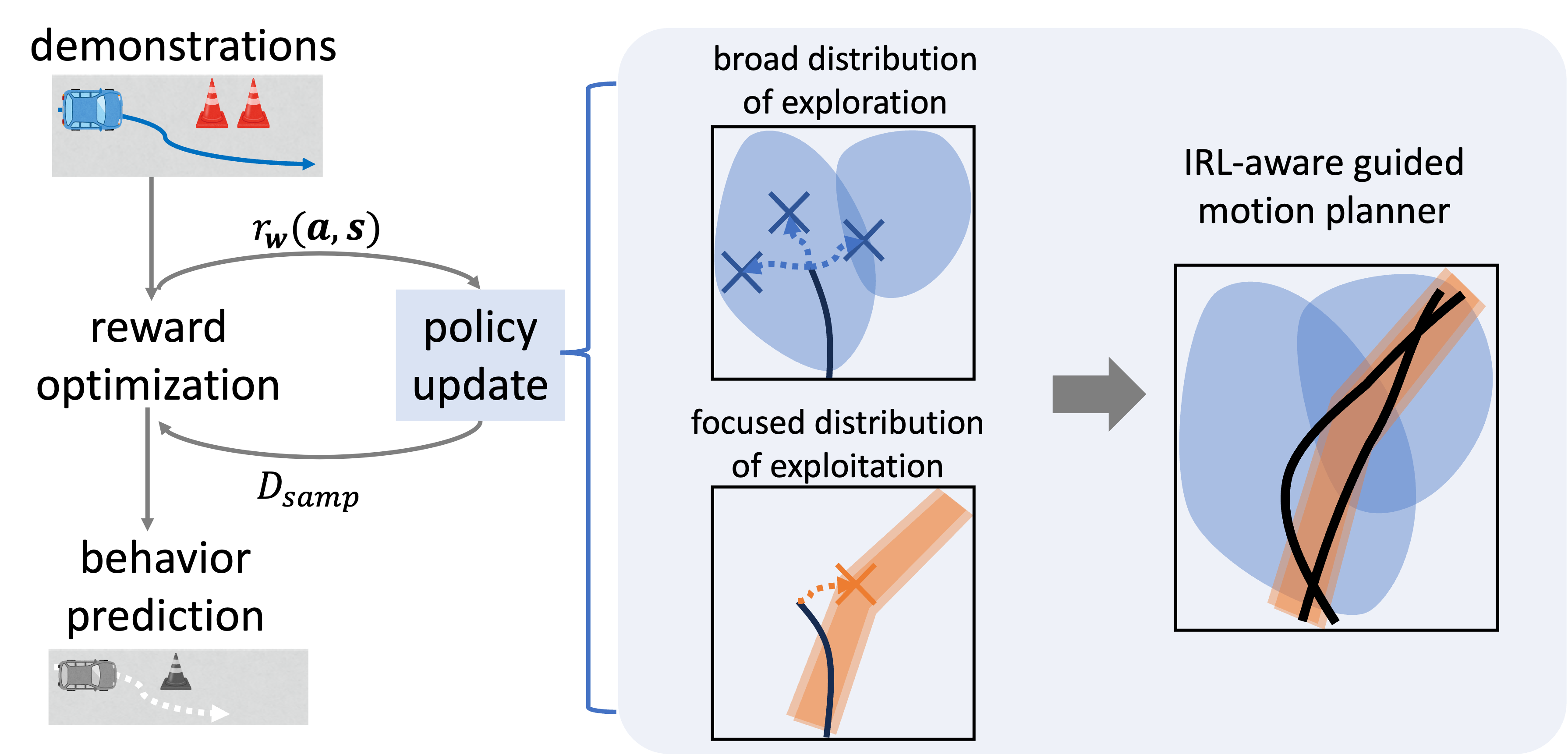
Figure 2: A motion planner leveraging demonstration information for improving the efficiency and stability of learning in continuous-state inverse reinforcement learning.
Furthermore, in order to realize a continuous and safe driving behavior model, it is necessary to explicitly address the inherent characteristics of real-world data. Due to safety constraints, failure events such as collisions or serious traffic violations occur only rarely, resulting in sparsity in the collected data. Under such conditions, conventional inverse reinforcement learning methods based on state visitation frequencies suffer from high variance in reward estimation, making it difficult to achieve both continuity and safety.
To address these challenges, rather than simply combining existing approaches, we propose a novel inverse reinforcement learning framework that introduces a behavior discriminator to directly model state-wise safety (Zhao et al., IEEE International Conference on Intelligent Transportation Systems, 2025). In this framework, the discriminator assigns safety labels to each state based on environmental context and is trained jointly with reward estimation. This enables the integration of fine-grained, state-level safety information without introducing additional constrained optimization. As a result, the proposed method achieves both stability and safety in continuous state spaces, even under conditions of sparse failure data (Fig. 3).
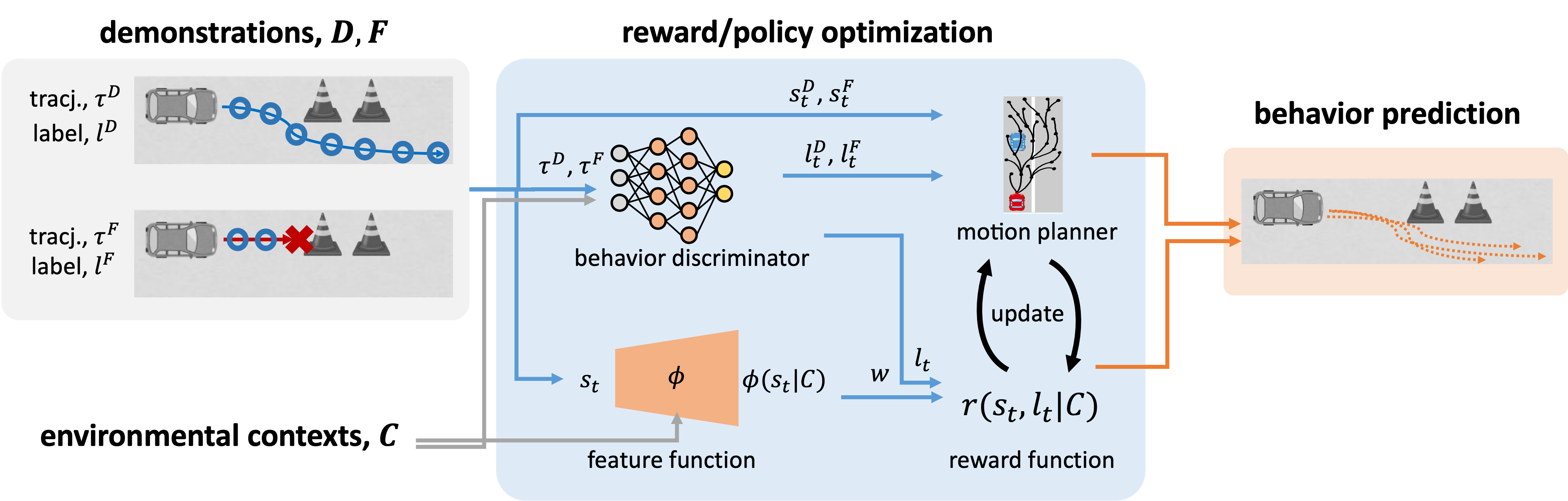
Figure 3: Framework of inverse reinforcement learning with temporally localized negative samples, incorporating a discriminative model for sparse negative data.
As described above, this study has progressively addressed the inherent imperfections of real-world driving data, including the temporal locality of hazardous behaviors, the challenges of sampling in continuous state spaces, and the sparsity of data arising from the rarity of failure events. Building upon these considerations, we ultimately developed an inverse reinforcement learning framework capable of modeling continuous and safe driving behavior.
—– Publication —–
M. Zhao and M. Shimosaka, “Inverse Reinforcement Learning with Failed Demonstrations towards Stable Driving Behavior Modeling,” 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Korea, Republic of, 2024, pp. 2537-2544, doi: 10.1109/IV55156.2024.10588690.
Minglu Zhao, and Masamichi Shimosaka. Stable Inverse Reinforcement Learning via Leveraged Guided Motion Planner for Driving Behavior Prediction. IEEE Access, pp. 87313-87326, 1 2025.
Minglu Zhao, Masamichi Shimosaka. Continuous Inverse Reinforcement Learning with State-wise Safety Constraints for Stable Driving Behavior Prediction Proceedings of the IEEE International Conference on Intelligent Transportation Systems (ITSC 2025), 9 2025.